# Index
# What are Artificial Intelligence, Machine Learning, and Deep Learning?
The term Machine Learning is often confused with the term Artificial Intelligence (abbreviated to AI), which however refers to a set of techniques, methodologies, and algorithms that includes those of Machine Learning (abbreviated to ML).
The objective of the AI field is to create intelligent agents, which can have a perception of the real world through sensors, make decisions thanks to their "intelligence", and finally implement them through actuators. If you want to make an analogy with a human being, you can think of sensors as the sense organs (eyes, ears,...), the intelligence is that of our brain and the actuators can be the hands, feet, or more generally the muscles.
However, the biological analogy is limited (opens new window), since it is not necessary for the sensors of an agent to detect physical phenomena, such as temperature or time, but it could detect data, relations, or inputs of any other kind.
Machine learning is generally considered as a subset of the AI field. Specifically, the term Machine Learning means the science of programming a machine so that it can learn to perform a task from the data, rather than through programming.
Deep Learning is a further subset of the Machine Learning field, more precisely an ensemble of techniques and algorithms that exploit neural networks for the solution of problems such as Computer Vision or Natural Language Understanding.
Virgilio's Mission
More specifically, Virgilio will provide you with guides to become experienced in the Machine Learning field, with a strong focus on Deep Learning techniques.
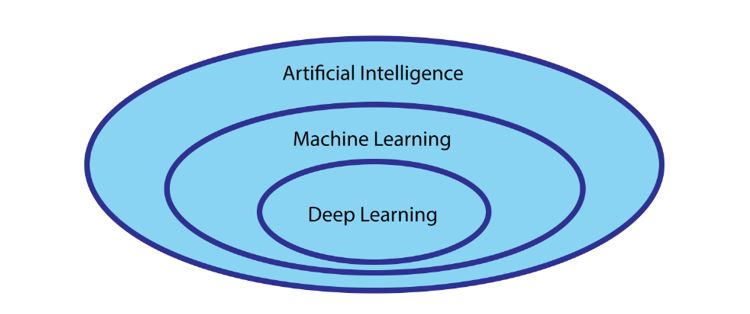
Hierarchical Relationship: Artificial Intelligence (AI), Machine Learning (ML), Deep Learning (DL)
A more engineering definition of Machine Learning is that given by Tom Mitchell: "A machine is learning from experience E with respect to task T and a metric of P, if its performance on T, measured with P, improves with experience E."
# A practical example:
This theoretical definition may be difficult to distinguish in practice, but it becomes more evident with an example, such as the autonomous driving system of a new generation car.
An autonomous car, in fact, can be considered as a whole an Artificial Intelligence system: it collects data from the real world (road, cars, road signs, speed) through sensors, possesses a set of "rules" of behavior that constitutes its intelligence ("if you are about to collide with an object, brake preventively") and a set of actuators implementing relative decisions (brakes, steering, ABS).
In this example, the AI system of the car has a sub-module of Machine Learning that allows it to improve over time, as the car "sees" different roads and situations, and increases its performance compared to some metric (safety, reaction time to braking, consumption).
Additional sub-modules can use Deep Learning techniques such as neural networks, trained to recognize the route of the road, the shapes of cars, distinguish them from those of trees and pedestrians, and so on.
# Differences from the algorithmic approach
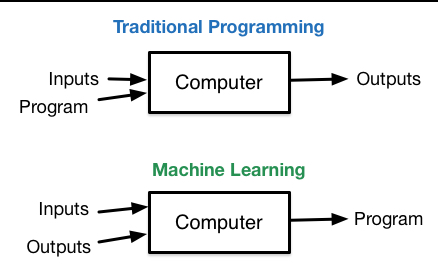
In computer science, the classic approach to the problem consists in designing a process (algorithm) that is then realized in a programming language (implementation), thus solving the problem in a deterministic fashion. It is important to note that there is no need for input data examples to produce the output considered correct.
This determinism implies the possibility to understand which action is taken at each step and why.
It is important to note that there is no need for input data examples to produce the output considered correct.
The approach of Machine Learning, at an intuitive level, consists instead in "seeing" a lot of input examples, each matched with the output considered correct, and programming the machine to detect the recurring patterns that occur in the data.
These patterns will then be used by the machine as "knowledge", to try to return the correct output, if a new input is provided (never seen before).
The process of feeding with data is called training and its result is a model (a set of parameters properly "adjusted" so that they recognize the patterns that interest us for the given problem).
Once a model is obtained, it can be used to predict the correct output to inputs that it has never "seen".
Generalization Capabilities
For a model, to be effective, it's crucial the ability to generalize to examples that it has never seen, otherwise it will work only after having being trained on all possible data!
Let's see some practical examples of how Machine Learning is applied in the real world.
It is an application of Machine Learning:
An "intelligent" spam email filter, which the more spam emails it processes, the more effective it becomes in recognizing and distinguishing them from useful emails.
A recognizer of hand-drawn figures or symbols, such as numbers, letters, or figures.
A system of customization of content suggested based on what you've already seen (Netflix that recommends the next movie to watch, Facebook that suggests groups that might interest you, Amazon that shows products often purchased together).
A sentiment analysis system capable of extracting important information from tweets or other data generated by humans about a particular event or character. For example, you can do a sentimental analysis of the "Donald Trump" concept during elections, and understand how it is perceived by people who post tweets about it (negative, positive, neutral...).
A system of writing assistance that, as the text is composed, foresees the next words and suggests them. Examples of this system are extremely popular, such as the automatic completion of smartphones or the Facebook search bar.
A Computer Vision system that recognizes the model and brand of a car by "seeing" it with a sensor (typically a video camera).
We also see some counter-examples.
It is not a Machine Learning application:
A search engine based on keywords: it does not improve with experience, and to make it more "intelligent" you have to program it explicitly.
A customer service interface that has pre-programmed responses to specific needs. For example, if I detect the word "ORDER" and an alphanumeric code in the customer's request message, then I show the status of the shipment identified by that code.
A sensor programmed to detect car number plates (e.g. the Safety Tutor system). Although it "sees" license plates and can, therefore, be confused with the concept of Computer Vision, it does not improve with experience, and its performance is determined solely by its programming at the design stage, where it is explicitly calibrated to detect a standard object (the license plate).
The famous mobile application Akinator, which tries to guess which historical or cinematic character the user is thinking about. Through a series of targeted questions (does he have hair? is he an alien? appears in Star Wars?) it explores a database of characters and by asking questions, by exclusion, it arrives at the answer. This, although it may seem like an "intelligent" program, is not really: it doesn't learn by improving with experience without being programmed to do so and follows a deterministic process easily explained by a human being.
# Why to use Machine Learning techniques
Imagine having to create a spam email filter with traditional programming techniques:
First, we would try to understand what the typical spam email looks like. We might notice that some words or phrases (for example "For Yourself", "Occasion", "Free only for today!") tend to appear often in annoying spam emails. Maybe we could notice further patterns in other parts of the mail, for example in the string representing the sender's mailbox, or that several emails are received from the same mailboxes in a few days.
We would write an algorithm to detect these patterns that we have noticed, for example using regular expressions to detect sequences of "suspicious" words and the algorithm would report as spam an email that contains a number of these patterns.
We would test the program and repeat steps 1 and 2 until we get a satisfactory version that signals malicious emails fairly accurately.
It's easy to see the program would very soon become a vast set of complex "hard-coded" rules, chaotic and complicated to maintain, needed to be added manually as new approaches to fool it will be used.
Instead, a spam filter consisting of a Machine Learning model would automatically learn which sentences, words, and patterns are valid indicators of spam danger and could be updated every time an email is recognized as a new type of spam. The program is much shorter, easy to maintain, and accurate in recognition.
In summary, Machine Learning techniques are appropriate for:
Fluid environments, where the problem constantly changes and in an unpredictable way (a mountain road never "seen" before, an email containing words never encountered, an unknown pattern in the peaks of users on a website).
Complex problems where the traditional approach would be impracticable or would lead to "Frankenstein" of code with high maintenance cost. The Machine Learning approach can significantly simplify the code and achieve better performance.
Get information about complex problems and discover patterns through large amounts of data.
# Conclusions
Now you should be more comfortable with high-level ideas of the concepts of AI and ML, and every time you see a term you'll know how to contextualize it.
You will also see how the terms are crippled and misused, and maybe you could recommend this guide to the next person to clarify his ideas!
In the next guide you will learn what do you need in order to start your Machine Learning journey!