# Index
# The three elements
Today, every area of science and economy has access to a quantity of data unimaginable even a decade ago.
In addition to this, today there is abundant and inexpensive computing capacity available through cloud service providers.
It is also important that international research is excited about machine learning topics, and therefore proceeds expeditiously in the development of increasingly effective techniques.
Parallel to this, the engineering world creates the ML toolbox by adjusting itself accordingly: wonderful frameworks and high-level interfaces to apply ML techniques quickly, going towards more user-friendly "enablers".
Keras, a high-level framework that allows you to train a deep neural network in 15 lines of code, is a perfect example of this phenomenon. In the same way, cloud providers offer you the possibility to host on their machines your ML models, with powerful logic that allows you to build a complete AI/ML start-up from your laptop.
The topics listed above have the following natural consequence:
Today, more than ever (and an enormity compared to 5 years ago) it is easy and affordable for everyone to start practicing ML in everyday problems, and it is an obligation in the shoes of a company that wants to remain competitive in a market that runs at a crazy speed.
Let's see which elements do you need to get started.
# Data
Data comes from the Latin Datus, which means fact, happened. Building ML programs means exploiting something that has already happened in the past (the data) to discover recurring patterns that suggest how to act in the future.
Building traditional programs is a tiring task. It requires that every single piece is built and then these are composed. It's not too different from building a house. Bricks are the modules that make it up and the house is the program in its entirety.
When it comes to Machine Learning applications, however, the matter is different. An ML program is something that we don't write ourselves, but rather something that we understand by observing and processing data.
A good analogy can be the following:
While building traditional software looks more similar to building a brick house, Machine Learning is similar to food cultivation. Cultivation leverages the earth to do most of the work. The farmer "guides" the land, supervises it, and then picks up the fruits. Likewise, thanks to Machine Learning, the programmer tries to make the data do the bulk of the work. Growers combine seeds with land to grow plants while engineers combine data with algorithms to grow programs.
It is therefore trivial to understand that if the data is to do the bulk of the work, the quality (and quantity) of the latter is strictly necessary for a model to make accurate predictions, or in general to extract knowledge effectively from them.
Mountains of Data
Today there is a large amount of data available to start practicing machine learning and discover its potential. Let's see how we can get the existing ones and how they can be useful in solving our problems.
# Free available data
Be happy! A lot of data is free and easy to download! Let's see the main options:
- Kaggle (opens new window) is the go-to platform for data in general: it's a Machine Learning challenges website and hosts an enormous quantity of datasets and analysis done by people on them. Subscribe now.
- UCI Datasets (opens new window) is a free and immediate platform for finding thousands of datasets and their metadata.
- U.S. Government open data (opens new window)
- UK Governement open data (opens new window)
- EU open data (opens new window)
- A very long list from Forbes (opens new window)
# Collect and label your own data
Data collection is a huge and critical topic, which technical details go outside the scope of this guide. We'll see in a dedicated Purgatorio's guide on how to collect huge quantities of data through scraping and other sources. To first taste the awesome free tools that we can use, take a look at the ones from Digital Methods (opens new window)!
# Look under the bed
More and more organizations are realizing that they are sitting in a gold mine. Years and years of historical data, from machines, conversation logs, transactions, or sensor measurements are only waiting for you! They probably hide a tremendous value to be unlocked, so why not take a look at that relational database!
The bottom line is: If you have a lot of data coming from a business process, probably they are worth their bytes in gold (uh, this analogy doesn't seem to fit well).
# Ask "why?" about Data
If we are aware of the five-whys (opens new window), it's one of the key techniques behind critical thinking. With so much data and with the end-results being data-dependent, it's so important to get the data part right.
So let's know-our-data before performing any actions or tasks or transformations on it. Let us know everything we need to know about the source and nature of the data we will be learning about, processing, transforming, analyzing, and training. There is a whole section dedicated to this aspect and perspective about data on this AI/ML/DL GitHub resource (opens new window).
Do scavenge through the material, the notebooks, presentations, and videos under this section. Unfortunately, we focus much less on critical thinking, which is a highly-potent ingredient needed when working with mathematics and sciences. Another good example would be looking at this online course "Calling Bullshit" (opens new window).
# Know-how
Doing data science is not simple. It will never be if you want to fully understand the mathematical processes behind the elegant models offered by high-level interfaces such as Keras. Learn to hate those who say "learn data science in 6 weeks". In one sense it's totally false, in the other it's disrespectful to those who study these issues for years, learning new things every day. This does not mean that we should be discouraged, on the contrary! Virgilio is here to help you in this fascinating process.
If you are a student or a technician in general who wants to experience these innovative themes first hand, follow the path that has been prepared for you starting from Purgatorio, and with the right time and determination, you will get incredible results.
If you are just interested in knowing what know-how is needed (for example in order to form a team that can develop large data science projects in your company) here are some tips for you.
Let's see what stages the process of developing a DS project consists of:
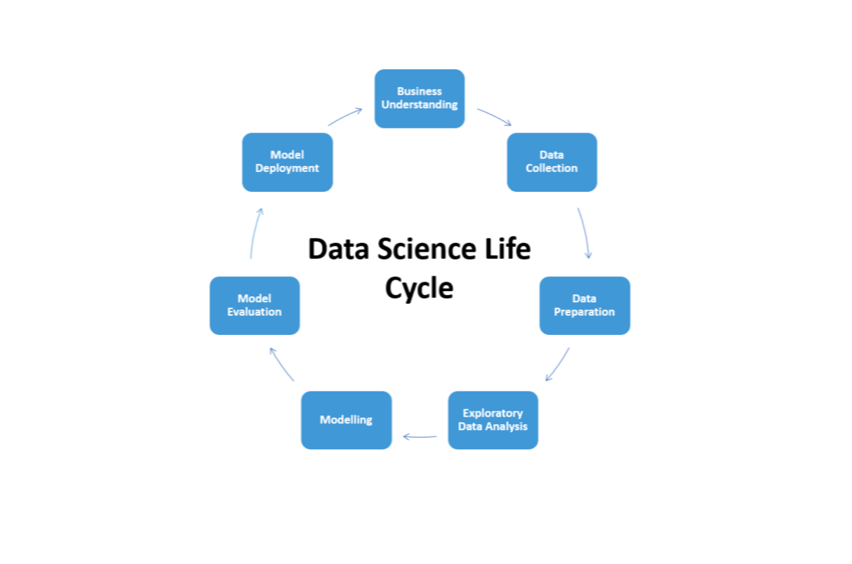
Let's have a look.
Once you have a good Business Understanding of the application that you want to develop to solve the problem, the data science cycle usually consists of experimenting with solutions in an iterative way by collecting data, shaping the problem and developing ML models.
Data collection consists of putting together data sources, building pipelines to pre-process them, and having a place to put them on hold for analysis.
Data Preparation consists of feature engineering (i.e. combining existing data in a meaningful way), training models, and evaluating their performance.
Exploratory Data Analysis is the phase where you explore and visualize your data, in order to catch important relationships and features that can help you in choosing the way you will develop a model.
Modelling is the phase where you use your data to train a Machine Learning (or Deep Learning) model that will be able to predict on never-seen data.
Model Evaluation consists of evaluating the performance of your model in the real-life scenario of the problem you want to solve.
Model Deployment is the phase where you make available your trained model to consumers.
After the deployment, you have to monitor the performances of your model and soon it may have to be modified as requirements change.
Because of this, the Data Science process is not One-Shot, but it's highly iterative and incremental (opens new window).
# The Data Science Team
After the deployment, and soon it may have to be modified as requirements change.
As you can easily guess, the Data Science process involves different figures for its success, even if the web services provided by large technology companies allow anyone to start developing ML solutions without worrying about the integration or management of the underlying systems.
These figures have blurred boundaries in terms of skills and knowledge, and in general, the ideal would be for each individual to be able to move with agility between the different tasks of the data science process. If this is possible for small scale projects, it is true that the needs of a company often require the coordinated effort of several people to be successful.
Names like "data scientist" or "data engineer" are described differently depending on the source. Here at Virgilio, we believe that the classification made by KDNuggets (opens new window) is the most comprehensive and clear.
In this awesome blog post (opens new window) you can find in detail the differences between these figures.
If you're just thinking about learning everything you need on your own, you're in the right place! Starting from Purgatorio our purpose is to educate a "liquid" figure who can move around among the different tasks and parts of the data science process.
Sooner or later you'll have to choose something to specialize in, maybe data visualization or model architecture, but before then the path we propose here at Virgilio is mixed between these "predefined" figures and contains all the interdisciplinary topics that a member of a data science team should at least be aware of.
Now that you know what know-how you need for your ML projects, let's take a look at the requirements in terms of computational resources.
# Computational Power
The third and final element that you have is computational power. The calculations that most of the time you find yourself doing when experimenting with Machine Learning are multiplications between matrices.
Then, in the subset of ML techniques called Deep Learning, neural networks are particularly hungry for these calculations.
In the past decades, such calculations were made directly using the CPU of computers, but they proved insufficient to train the most complex networks.
Fortunately, we are helped by GPUs (graphical processor units), whose job is exactly to do matrix calculations! In fact, in the world of gaming and video computing in general, these kinds of calculations are what happens daily behind the scenes of video games and 3D graphics in general.
In particular, the main factor that indicates the use of GPUs in Machine Learning calculations is the amount of video memory (expressed in GigaBytes) that the card has.
Damn it! We have to buy an extreme gaming PC with 4 GPUs!
Kidding, please don't do that.
Thanks to the internet connection and cloud providers, nowadays it is much more convenient to use machines prepared and maintained by companies like Amazon or Google, instead of investing money in physical hardware.
# Cloudy Days
Outsourcing is the main driver of the human society progress (opens new window). Imagine one of the first farmers in 20,000 B.C. He is used to carrying out the entire production process on his own: he tames and cultivates the wheat, picks it up, and crushes it into small parts. He then uses it to create various products, such as flour, ready-made doughs, or a primitive form of bread.
Nowadays, however, an individual or an organization can only deal with one of the previous sub-processes, and specialize highly in that. For example, by choosing to specialize in the production of bread, they could learn how to produce many forms of bread, look for new ones, improve the flavor and optimize all these processes, forming specific and specialized know-how with respect to the production of bread.
This process, the progressive specialization of human activities, is the basis of the technical progress of our species. It is clearly based on outsourcing! If all the sub-processes preceding the production of bread were to disappear, the baker would be destined to close down. How does it grow wheat? How does it prevent insects from ruining it? How does it pay for, manage, and maintain the presses that crush it and make it flour?
In the same way, companies today outsource as much as possible all processes that are not essential to the company's know-how: in doing so, everyone can do "what they do best".
The same trend is being seen today in the use of the software. It is more common than ever to use services provided through the network to solve sub-problems that companies do not want to worry about, such as the management of physical machines that host their applications, or they want to have their data from anywhere in the world in a safe and reliable way!
It is therefore not surprising that Cloud Computing (opens new window) is becoming a very important part of the software market, thanks to the flexibility and reduced costs that this entails.
The race towards the monopoly (opens new window) of the cloud market is fierce, particularly between Amazon (with AWS) and Microsoft (Azure).
How does this come in handy for Machine Learning?
With a few clicks, you can deploy files and files of high-performance machines, managed in a transparent way, and especially with on-demand capabilities. This fact drastically reduces the costs and complexity of developing complex software and solutions, all from a dedicated web interface or client. It also allows you to serve solutions quickly, flexibly, and without the classic problems of large-scale computing that today's distributed systems require. Being able to scale from one device to millions simply by turning on hundreds of self-managed and paid-for machines, is an outstanding business and research enabler.
Recently, all large tech companies have started to provide (and invest heavily) in providing services related to AI and ML issues. Emerging (and required) figures such as the data engineer or data scientist are able to achieve incredible levels of productivity and business through end-to-end platforms that cover the entire development cycle of AI and ML solutions. Some examples are AWS Sagemaker (opens new window) or Azure Machine Learning Studio (opens new window).
To start experimenting in a simple way there are even solutions such as Google Colab (opens new window), a free Google tool that allows you to use Jupyter notebooks on your machines, without having to worry about installing packages or managing memory. It's also totally free!
We have created a fantastic list (opens new window) that compares all cloud solutions in terms of cost and performance.
Don't believe who tells you that you need to buy a high-performance machine to make ML. He probably lives in 2010!
# If you still have to buy a machine
Suppose you still have to buy a calculator for other needs, let's see which are some good options:
- These Quora answers (opens new window) are straightforward (you can notice that they suggest leveraging the cloud-first approach).
- This (opens new window) Medium article shows you how to build an 800 dollars rig for Machine Learning.
As we have seen the important component for ML calculations is the GPU, in particular the amount of video memory that owns. WARNING: You definitely want to have a GPU compatible with Cuda (opens new window), the parallelization platform of Nvidia, the largest GPU manufacturer.
This article (opens new window) explains how to choose a GPU that supports Cuda.
# Conclusions
We have seen how the three elements (data, know-how, and computing power) are strictly necessary to develop ML solutions for everyday problems.
If you are a student or just a curious cat you will have an easy time thanks to Google Colab and the free power it offers. If you're part of a team in a company thinking about starting to experiment with ML at scale, consider the ever richer and better ML services offered by the big technology cloud vendors.
In the next guide, we'll ask ourselves: do we really need Machine Learning?